スケジュールナースで時間割作成出来る?
Pythonまで使えば、フレキシブルに作成することが出来ると思います。
例として、Qiita記事 数理最適化による時間割作成
でのデータを基に実装してみます。
スケジュールナースの記述能力の高さを示すデモプロジェクトです。
マッピング
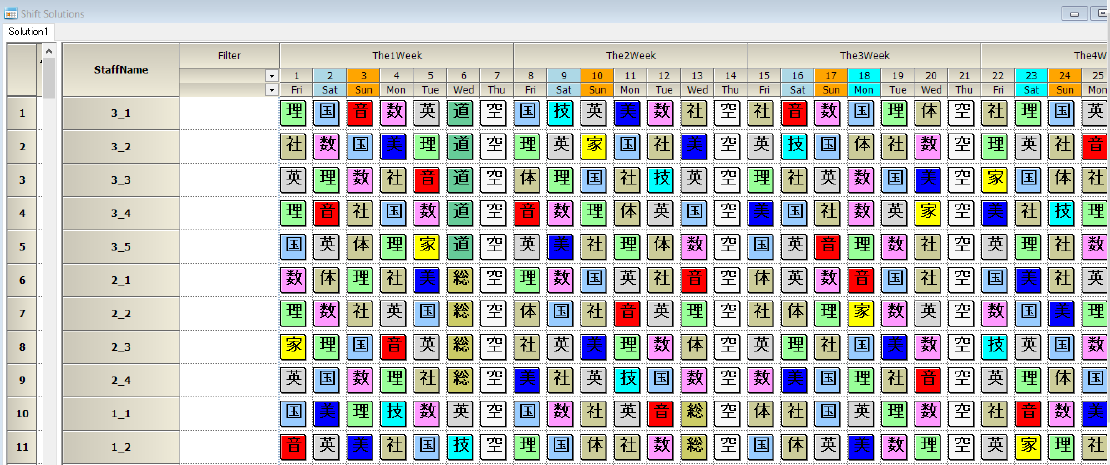
スケジュールナース、シフト勤務表では、スタッフ、Dayおよびシフトが変数対象となります。当然、そのままでは、時間割のイメージとにマッチしません。
そこで時間割を次のようにマッピングします。
| 項 | 時間割 | スケジュールナースプロジェクト |
|---|---|---|
| 1 | クラス | スタッフ |
| 2 | 限 | 曜日 |
| 3 | 曜日 | 週 |
| 4 | 科目 | シフト |
クラス名の定義
スタッフプロパティシート上に記述します。
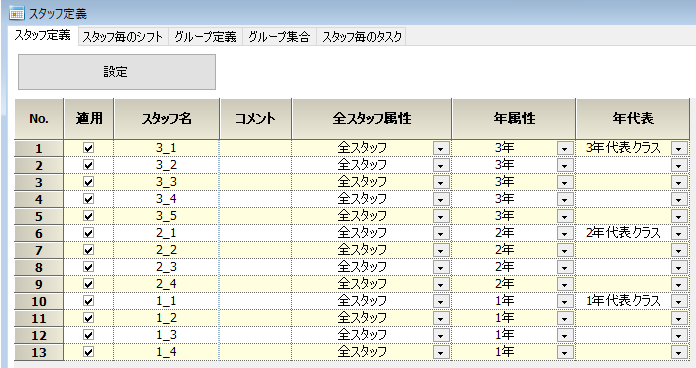
科目の定義
空シフトは、休み用に定義しています。
限、曜日の定義
1週間を7限と考えます。従い7限目まで対応可能です。Qiita記事では、月曜から金曜日まで定義されているので、
| 項 | 時間割 | スケジュールナース |
|---|---|---|
| 1 | 月曜 | 第一週 |
| 2 | 火曜 | 第二週 |
| 3 | 水曜 | 第三週 |
| 4 | 木曜 | 第四週 |
| 5 | 金曜 | 第五週 |
カレンダ設定は、どこでもよいのですが、5週間を定義しました。
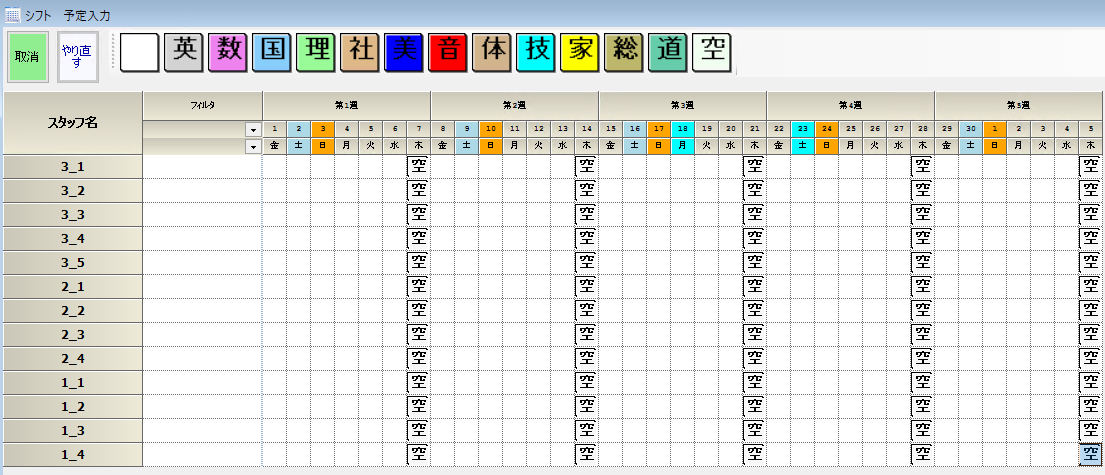
Qiita記事では、6限目まで定義されているので、7限目は、空シフトで埋めています。
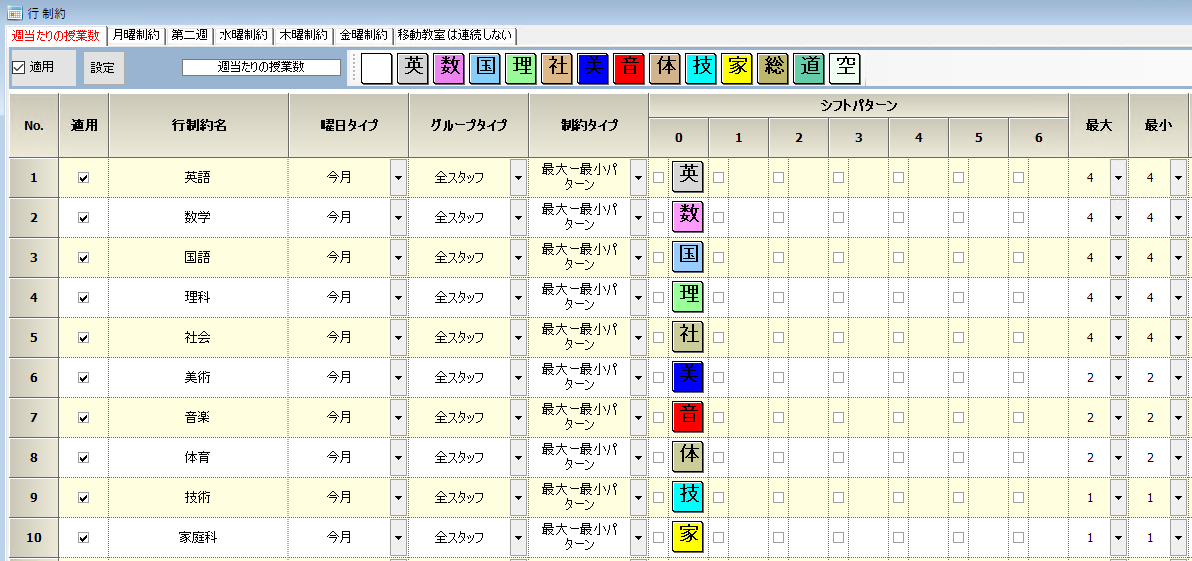
各教科は、1週間の必要授業数を行う
時間割上の1週間は、プロジェクト上今月期間全体になります。英国数社理については、週あたり4コマを制約します。以下同様に制約します。
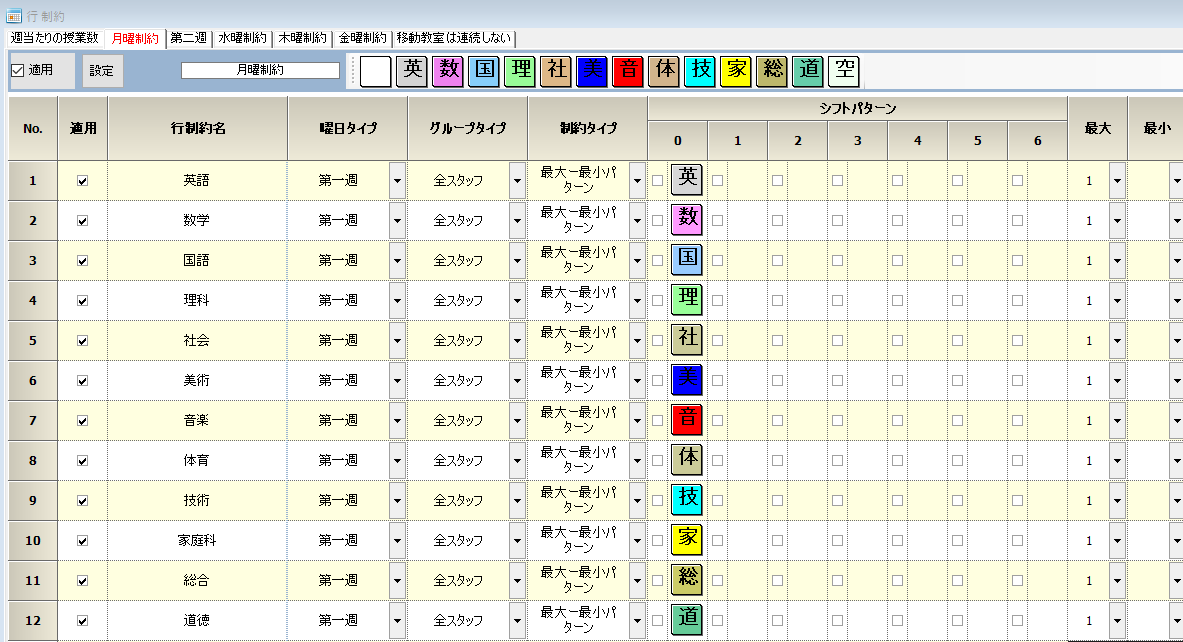
各教科は、1日の授業数の上下限を守る
Qiita記事を参照し、各科目の1日の授業数は、1以下としました。時間割上の1日は、プロジェクト上では、1週間です。これを時間割月~金まで記述することになるので、5週間に渡って同様の記述を行います。
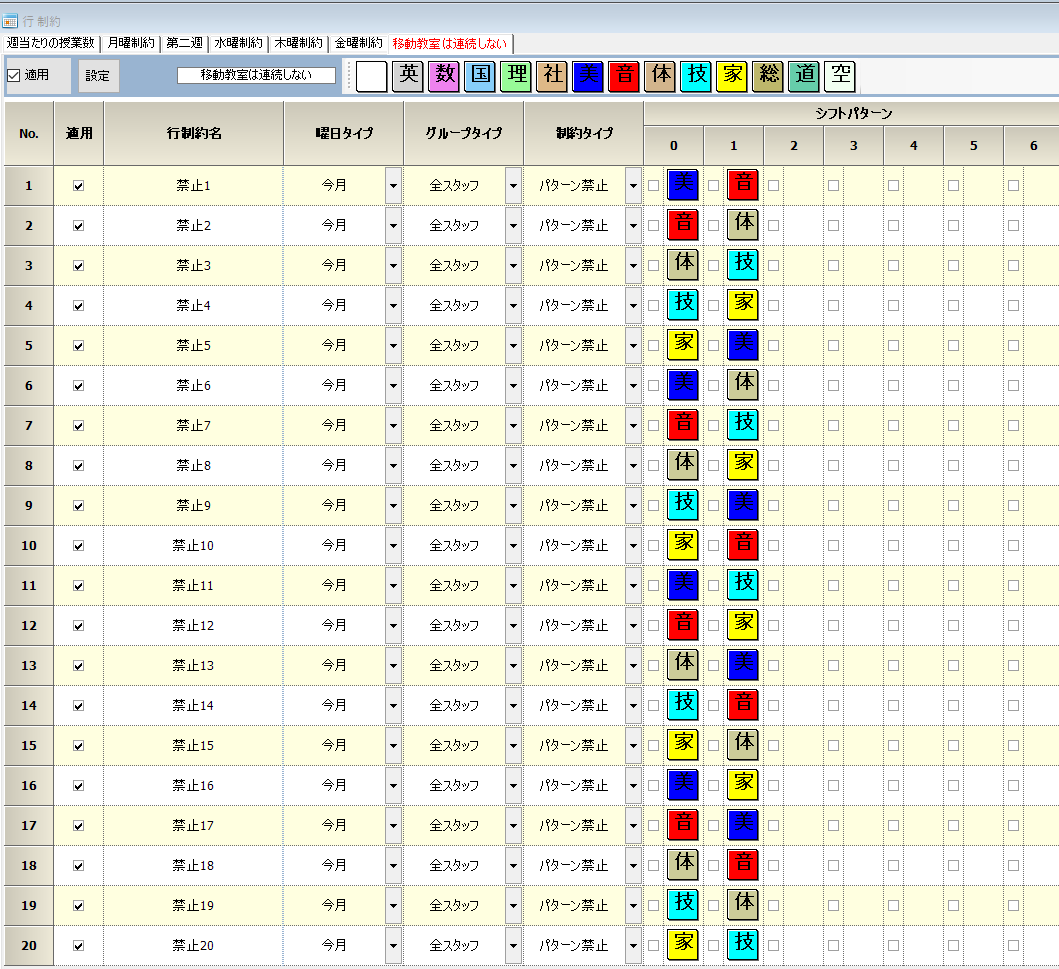
体育など移動教室は連続しない
体育、音楽、技術、家庭の全ての組合わせを禁止します。上で、同一科目は、時間割1日上で禁止しており、例えば体体は、記述する必要がありません。
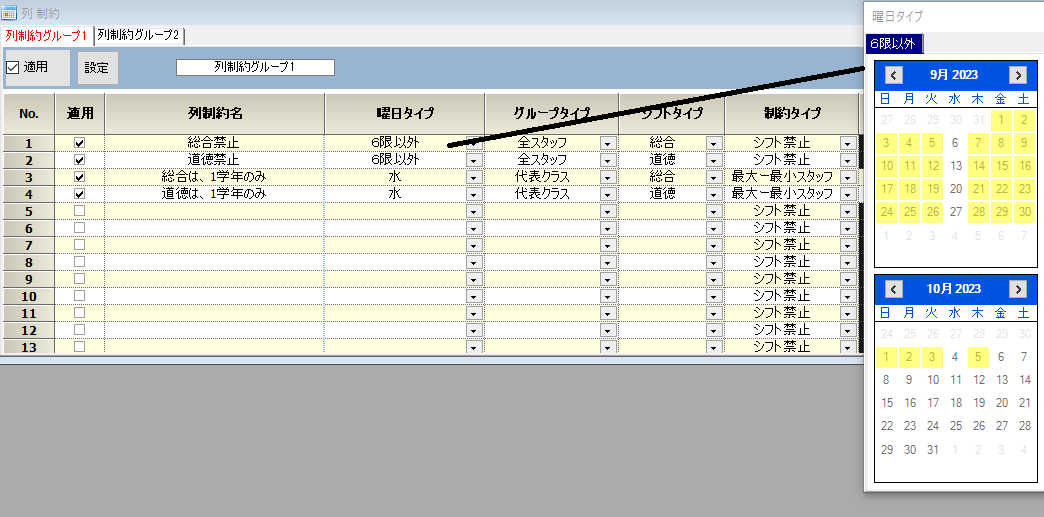
総合と道徳は6限に行う
列制約を用いて記述します。6限以外の総合と道徳は禁止します。
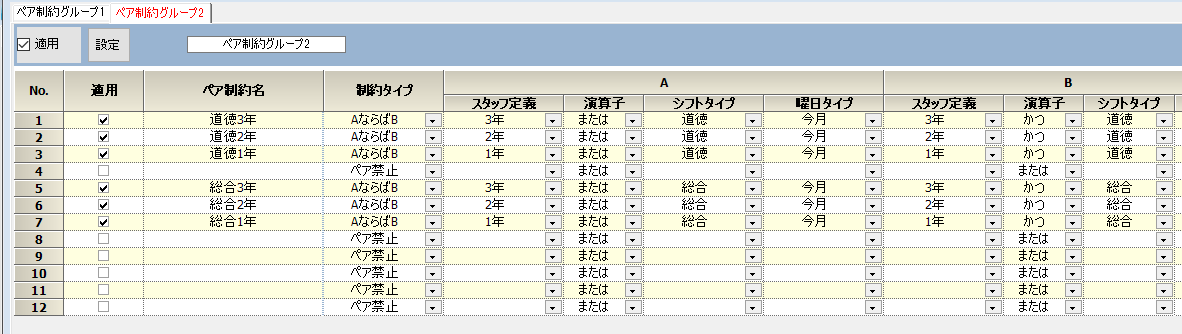
総合と道徳は学年で曜日を統一して行う
ペア制約を用いて記述します。最初の行は、3年のクラスのうち一つでも(または)道徳ならば、全3年クラスが(かつ)道徳になる、という制約です。
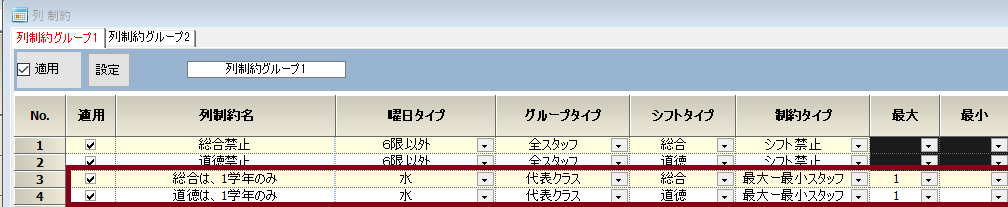
総合と道徳は異なる学年で同じ時間には行わない
列制約を用いて記述します。上で、学年を統一した動きとしているので、学年を代表する1クラスについて制約すれば十分です。
ここまでは、GUIで記述できました。GUIで記述する利点は、一つ一つ記述しながら、即求解し、記述の正当性を確認しながら進められることです。この作業は、意外に楽しいです。
以降は、GUIで記述するのが難しい、もしくは、Pythonで記述した方が楽なので、Pythonで記述します。
教員の制約
Qiita記事中のソースで、csvファイルをダウンロードしています。
lesson_df = pd.read_csv("https://raw.githubusercontent.com/ryosuke0010/opt_test/master/composition.csv")
このファイルを眺めてみると、grが学年列、clがクラス名であり、例えば3年1組の英語は、教員6という具合に、クラスが決まれば、担当科目の教員はこの表により決まることが分かります。
教員6は、3年1組以外にも全ての3年のクラスの英語授業を担当し、3年3組の総合と、道徳に関しても担当することが分かります。
gr,cl,英語,数学,国語 理科,社会,美術,音楽,体育,技術,家庭科,総合,道徳
3,1,教員6,教員9,教員15,教員14,教員18,教員0,教員1,教員2,教員5,教員21,教員9,教員9
3,2,教員6,教員9,教員15,教員14,教員20,教員0,教員1,教員2,教員5,教員21,教員2,教員2
3,3,教員6,教員11,教員15,教員13,教員18,教員0,教員1,教員2,教員5,教員21,教員6,教員6
3,4,教員6,教員9,教員15,教員13,教員18,教員0,教員1,教員2,教員5,教員21,教員18,教員18
3,5,教員6,教員9,教員15,教員13,教員18,教員0,教員1,教員2,教員5,教員21,教員15,教員15
2,1,教員7,教員10,教員16,教員12,教員19,教員0,教員1,教員3,教員5,教員21,教員3,教員3
2,2,教員7,教員10,教員16,教員12,教員19,教員0,教員1,教員3,教員5,教員21,教員19,教員19
2,3,教員7,教員10,教員16,教員12,教員19,教員0,教員1,教員3,教員5,教員21,教員10,教員10
2,4,教員7,教員10,教員16,教員12,教員19,教員0,教員1,教員3,教員5,教員21,教員7,教員7
1,1,教員8,教員11,教員17,教員13,教員20,教員0,教員1,教員4,教員5,教員21,教員11,教員11
1,2,教員8,教員11,教員17,教員13,教員20,教員0,教員1,教員4,教員5,教員21,教員17,教員17
1,3,教員8,教員11,教員17,教員14,教員20,教員0,教員1,教員4,教員5,教員21,教員14,教員14
1,4,教員8,教員11,教員17,教員14,教員20,教員0,教員1,教員4,教員5,教員21,教員8,教員8
1教員が同一限に担当するのは、1科目
1教員が同一限に2個以上担当することがないようにします。
各教員のあり得るシフト(科目)を列挙して、同一限で、その総和が1以下となるように制約します。下記ソースがその記述部です。
def empty_work(dic,dic_units,week):#1教員あたり、同一限で2個以上の授業は不可 1日あたりの授業数平準化
for name in dic:
week_vlist=[]
for day in week:
if day in 木:
continue
vlist=[]
for tp in dic[name]:
subject=list_of_rows[0][tp[1]]
Class=tp[0]-1
#print(Class,day,subject)
v=sc3.GetShiftVar(Class,day,subject)
vlist.append(v)
sc3.AddHard(sc3.SeqLE(0,1,vlist),'教員ひとりにつき同一コマは一個以下_'+name)
v=sc3.Or(vlist)
week_vlist.append(v)
div=dic_units[name]/5
print(name+' コマ数平準化',math.floor(div),math.ceil(div))
sc3.AddHard(sc3.SeqLE(math.floor(div),math.ceil(div),week_vlist),name)
各教師が1日に行う授業数は平準化を行う。各曜日で大きく違わないようにする
これは、私が勝手に想像した制約で、Qiita記事ではありません。各教員毎に担当コマ数は異なるので、各教員毎の平準化を行った方がよいだろうという、勝手な判断によるものです。
教師が決まれば、時間割一日あたりの平均コマ数は確定します。単純に平均値のfloorとceilにより上限下限をハード制約で記述しています。今回は、ハード制約で記述していて、解が存在しました。ここで解がないようなら、ソフト制約に変更する必要がありましたが、解は存在したので、ハード制約のまま、としています。 以上の記述も上のソースで行っています。
各学年毎に、所属学年の教師が、各限に行う授業数は、平準化を行う。(空コマ数の各限毎の平準化と同義)
これも、Qiita記事にはありません。各学年毎の各コマ毎の授業数上の平準化を行うものです。学年毎に、各コマの平均コマ数は決まるので、単純に平均値のfloorとceilにより上限下限をハード制約で記述しています。今回は、ハード制約で記述していて、解が存在しました。ここで解がないようなら、ソフト制約に変更する必要がありましたが、解は存在したので、ハード制約のまま、としています。 以上の記述を下のソースで行っています。
def empty_frame_avg(dic,grade_list,empty_avg_frames,week):#学年毎の1限あたりの空き教員数の平準化
for day in week:
Vlist={}
if day in 木:
continue
for name in dic:
vlist=[]
for tp in dic[name]:
subject=list_of_rows[0][tp[1]]
Class=tp[0]-1
#print(Class,day,subject)
v=sc3.GetShiftVar(Class,day,subject)
vlist.append(v)
v=sc3.Or(vlist)
grade=get_grade(name,grade_list)
if grade not in Vlist:
list=[]
list.append(~v)
Vlist[grade]=list
else:
Vlist[grade].append(~v)
for item in Vlist:
f=empty_avg_frames[item]
s=str(item)+'年空き教員数平準化 '+get_period(day)
print(s,math.floor(f),math.ceil(f))
sc3.AddHard(sc3.SeqLE(math.floor(f),math.ceil(f),Vlist[item]),s)
全体ソース
import sc3
import csv
import urllib.request
import math
import re
def get_grade(name,grade_list):
t_ind = int(re.sub(r"\D", "", name))
grade=grade_list[t_ind]
return grade
def get_period(day):
if day in 金:
return '1限'
elif day in 土:
return '2限'
elif day in 日:
return '3限'
elif day in 月:
return '4限'
elif day in 火:
return '5限'
elif day in 水:
return '6限'
def empty_work(dic,dic_units,week):#1教員あたり、同一限で2個以上の授業は不可 1日あたりの授業数平準化
for name in dic:
week_vlist=[]
for day in week:
if day in 木:
continue
vlist=[]
for tp in dic[name]:
subject=list_of_rows[0][tp[1]]
Class=tp[0]-1
#print(Class,day,subject)
v=sc3.GetShiftVar(Class,day,subject)
vlist.append(v)
sc3.AddHard(sc3.SeqLE(0,1,vlist),'教員ひとりにつき同一コマは一個以下_'+name)
v=sc3.Or(vlist)
week_vlist.append(v)
div=dic_units[name]/5
print(name+' コマ数平準化',math.floor(div),math.ceil(div))
sc3.AddHard(sc3.SeqLE(math.floor(div),math.ceil(div),week_vlist),name)
def empty_frame_avg(dic,grade_list,empty_avg_frames,week):#学年毎の1限あたりの空き教員数の平準化
for day in week:
Vlist={}
if day in 木:
continue
for name in dic:
vlist=[]
for tp in dic[name]:
subject=list_of_rows[0][tp[1]]
Class=tp[0]-1
#print(Class,day,subject)
v=sc3.GetShiftVar(Class,day,subject)
vlist.append(v)
v=sc3.Or(vlist)
grade=get_grade(name,grade_list)
if grade not in Vlist:
list=[]
list.append(~v)
Vlist[grade]=list
else:
Vlist[grade].append(~v)
for item in Vlist:
f=empty_avg_frames[item]
s=str(item)+'年空き教員数平準化 '+get_period(day)
print(s,math.floor(f),math.ceil(f))
sc3.AddHard(sc3.SeqLE(math.floor(f),math.ceil(f),Vlist[item]),s)
def get_list_of_rows():
url="https://raw.githubusercontent.com/ryosuke0010/opt_test/master/composition.csv"
response = urllib.request.urlopen(url)
lines = [l.decode('utf-8') for l in response.readlines()]
#print(lines)
reader=csv.reader(lines)
list_of_rows=list(reader)
return list_of_rows
def get_teacher(Class,subject,list_of_rows):
ind= list_of_rows[0].index(subject)
return list_of_rows[Class+1][ind]
def get_teacher_ind(Class,subject,list_of_rows):
name=get_teacher(Class,subject,list_of_rows)
t_ind = int(re.sub(r"\D", "", name))
return t_ind
def post_main():
print('Executing Post Main')
grade_list=[3,3,3,2,1,1,3,2,1,3,2,1,2,1,1,3,2,1,3,2,3,2]
list_of_rows=get_list_of_rows()
tmap={}
grade_map={}
for Class in 全スタッフ:
for day in 今月:
if day in 木:
continue
subject=shift_solution[Class][day]
t_ind=get_teacher_ind(Class,subject,list_of_rows)
grade=grade_list[t_ind]
if grade not in grade_map:
list=[0]* len(今月)
list[day]+=1
grade_map[grade]=list
else:
grade_map[grade][day]+=1
#print(teacher,subject)
Day=int(day/7)
if t_ind not in tmap:
list=[0,0,0,0,0]
list[Day]+=1
tmap[t_ind]=list
else:
tmap[t_ind][Day]+=1
tmap2=sorted(tmap.items())
#print(tmap2)
#print(grade_map)
print('各教員の各曜日に対する授業数平準化結果')
print(' 月 火 水 木 金')
for t in tmap2:
print('教員'+str(t))
print('')
print('各学年毎の各限に対する授業数の平準化=空き授業数の平準化結果')
for g in grade_map:
print(str(g)+'学年:')
print(' 月 火 水 木 金')
for i in range(6):
print(str(i+1)+'限 ',end='')
for day in range(5):
print(grade_map[g][day*7+i],' ',end='')
print('')
print('')
list_of_rows=get_list_of_rows()
print(list_of_rows)
dic={}
dic_units={}
grade_units={}
grade_list=[3,3,3,2,1,1,3,2,1,3,2,1,2,1,1,3,2,1,3,2,3,2]
for list in list_of_rows:
col=0
subject_units=[0,0,4,4,4,4,4,2,2,2,1,1,1,1]
for item in list:
if '教員' in item:
if item not in dic:
l=[]
c=list.index(item)
dic_units[item]=subject_units[c]
l.append((list_of_rows.index(list),list.index(item)))
dic[item]=l
else:
dic_units[item]+=subject_units[col]
dic[item].append((list_of_rows.index(list),col))
col+=1
for item in dic_units:
grade=get_grade(item,grade_list)
if grade not in grade_units:
grade_units[grade]=dic_units[item]
else:
grade_units[grade]+=dic_units[item]
print(grade_units)
print(dic)
print(dic_units)
empty_work(dic,dic_units,第一週)#月
empty_work(dic,dic_units,第二週)#火
empty_work(dic,dic_units,第三週)#水
empty_work(dic,dic_units,第四週)#木
empty_work(dic,dic_units,第五週)#金
teachers={1:grade_list.count(1),2:grade_list.count(2),3:grade_list.count(3)}
print(teachers)
empty_avg_frames={}
for t in teachers:
empty_avg_frames[t]=(teachers[t]*6*5-grade_units[t])/(6*5)#平均空きコマ数を求めて、そのfloor,ceilを制約範囲とする
print(empty_avg_frames)
empty_frame_avg(dic,grade_list,empty_avg_frames,第一週)#月
empty_frame_avg(dic,grade_list,empty_avg_frames,第二週)#火
empty_frame_avg(dic,grade_list,empty_avg_frames,第三週)#水
empty_frame_avg(dic,grade_list,empty_avg_frames,第四週)#木
empty_frame_avg(dic,grade_list,empty_avg_frames,第五週)#金
解
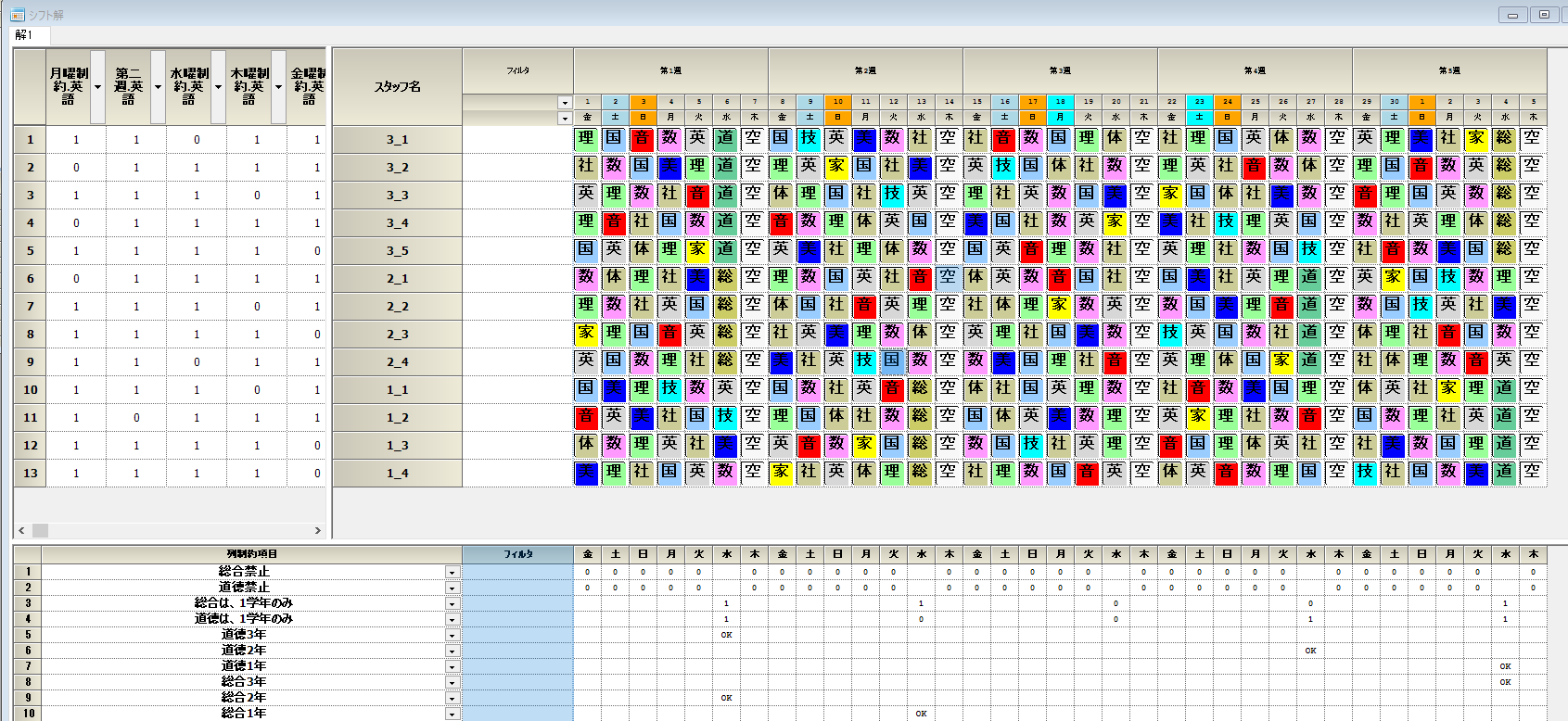
検証
解が出た後に、ポスト処理で、解の妥当性について検証しています。
最初は、各教員の月~金授業数に偏りがないかのチェックです。平均値についてfloor,ceilしているので、偏差は1以内となっています。
次に、各学年の授業数の偏りチェックです。これも平均値についてfloor,ceilしているので、偏差は1以内となっています。
制約した通りに動いているようです。
以上のpython記述部は、post_mainです。
Algorithm 1 Solving Process Started..
Python プロパティファイルの生成が終わりました。
_____________________________________
| | | |
| Weight | Errors | Cost |
|___________|___________|_____________|
| | | |
|___________|___________|_____________|
| | |
| Total | 0 |
|_______________________|_____________|
*********UB=0(0) 1.651(cpu sec)
o 0(0)
解探索が終了しました。 3 (秒)
解が得られました。
ポスト処理を実行します。ソルバを呼び出し中です。
Executing Post Main
各教員の各曜日に対する授業数平準化結果
月 火 水 木 金
教員(0, [6, 5, 5, 5, 5])
教員(1, [5, 5, 5, 6, 5])
教員(2, [2, 3, 2, 3, 2])
教員(3, [2, 2, 2, 2, 2])
教員(4, [1, 2, 2, 2, 1])
教員(5, [2, 3, 2, 3, 3])
教員(6, [4, 5, 4, 4, 5])
教員(7, [4, 4, 3, 4, 3])
教員(8, [4, 4, 4, 3, 3])
教員(9, [4, 3, 4, 3, 4])
教員(10, [4, 3, 4, 3, 4])
教員(11, [4, 4, 5, 4, 5])
教員(12, [4, 3, 3, 3, 3])
教員(13, [4, 4, 4, 4, 4])
教員(14, [4, 3, 3, 4, 4])
教員(15, [5, 4, 5, 4, 4])
教員(16, [3, 3, 3, 4, 3])
教員(17, [3, 4, 4, 3, 4])
教員(18, [3, 3, 4, 4, 4])
教員(19, [4, 4, 4, 3, 3])
教員(20, [4, 4, 4, 4, 4])
教員(21, [2, 3, 2, 3, 3])
各学年毎の各限に対する授業数の平準化=空き授業数の平準化結果
1学年:
月 火 水 木 金
1限 4 4 4 4 4
2限 4 4 4 4 4
3限 3 4 4 4 4
4限 4 4 4 3 4
5限 4 4 4 4 4
6限 3 4 4 4 4
3学年:
月 火 水 木 金
1限 5 5 5 5 5
2限 5 5 6 5 5
3限 6 5 5 6 6
4限 6 6 6 6 6
5限 5 5 6 6 5
6限 6 6 5 5 6
2学年:
月 火 水 木 金
1限 4 4 4 4 4
2限 4 4 3 4 4
3限 4 4 4 3 3
4限 3 3 3 4 3
5限 4 4 3 3 4
6限 4 3 4 4 3
ポスト処理を終了しました。 1 (秒)
求解速度
| アルゴリズム | 速度 | 備考 |
|---|---|---|
| 1 | 1.6秒 | |
| 2(Highs) | 982秒 | |
| Pulp(CBC) | 3.3秒 | 下記ソース(timetable3.py)参照 python3 timetable3.py |
| Pulp->MPS->Highs | 11秒 |
#ライブラリのインポート
import pandas as pd
import numpy as np
import pulp
import math
#基本情報のデータ
teacher_list = [f'教員{i}' for i in range(22)]
subject_list = ["英語","数学","国語","理科","社会","美術","音楽","体育","技術","家庭科","総合","道徳"]
grade_list = [1,2,3]
class_dict = {3:[1,2,3,4,5],2:[1,2,3,4],1:[1,2,3,4]}
teacher_dict = {t:g for t,g in zip(teacher_list,[3,3,3,2,1,1,3,2,1,3,2,1,2,1,1,3,2,1,3,2,3,2])} #教員の所属学年
period = [1,2,3,4,5,6]
week = ["月","火","水","木","金"]
Classroom_mobility = ["美術","音楽","体育","技術","家庭科"] #移動教室授業
six_period = ["総合","道徳"] #6限のみの授業
subject_dict = {s:n for s,n in zip(subject_list,[4,4,4,4,4,2,2,2,1,1,1,1])} #必要授業数
lesson_df = pd.read_csv("https://raw.githubusercontent.com/ryosuke0010/opt_test/master/composition.csv")
model = pulp.LpProblem("model",pulp.LpMinimize)
x = {}
#x_曜日_時限_学年_クラス_授業
for d in week:
for p in period:
for g in grade_list:
for c in class_dict[g]:
for s in subject_list:
x[d,p,g,c,s] = pulp.LpVariable(cat="Binary",name=f"x_{d}_{p}_{g}_{c}_{s}")
#(1)1 つの時限では必ず 1 つ授業を行う
for d in week:
for p in period:
for g in grade_list:
for c in class_dict[g]:
model += pulp.lpSum([x[d,p,g,c,s] for s in subject_list]) == 1
#(2)各教科sは1週間の必要授業数だけ行う
for g in grade_list:
for c in class_dict[g]:
for s in subject_list:
model += pulp.lpSum([x[d,p,g,c,s] for d in week for p in period]) == subject_dict[s]
#(3)教科は 1 日の授業数の上下限を守る
for d in week:
for g in grade_list:
for c in class_dict[g]:
for s in subject_list:
model += pulp.lpSum([x[d,p,g,c,s] for p in period]) <= 1
#(4)体育など移動教室は連続しない
for d in week:
for p in period[:5]:
for g in grade_list:
for c in class_dict[g]:
model += pulp.lpSum([x[d,p,g,c,s] + x[d,p+1,g,c,s] for s in Classroom_mobility]) <= 1
#(5)総合と道徳の制約
#➀総合と道徳は6限
for d in week:
for p in period[:5]:
for g in grade_list:
for c in class_dict[g]:
model += pulp.lpSum([x[d,p,g,c,s] for s in six_period]) == 0
#➁総合と道徳は学年で曜日を統一して行う
for d in week:
for g in grade_list:
for c in class_dict[g][:-1]:
for s in six_period:
model += x[d,6,g,c,s] == x[d,6,g,c+1,s]
#➂総合と道徳は異なる学年で同じ時間には行わない
for d in week:
for s in six_period:
model += pulp.lpSum(x[d,6,g,1,s] for g in grade_list) <= 1
flag={}
t_units={}
for g in grade_list:
for c in class_dict[g]:
for t in teacher_list:
for s in subject_list:
flag[g,c,t,s]=False
g_units={}
for g in grade_list:
for c in class_dict[g]:
for s in subject_list:
df = lesson_df[lesson_df["gr"] == g]
t = df[df["cl"] == c][s].values[0]
grade=teacher_dict[t]
flag[g,c,t,s]=True
if t not in t_units:
t_units[t]=subject_dict[s]
else:
t_units[t]+=subject_dict[s]
if grade not in g_units:
g_units[grade]=subject_dict[s]
else:
g_units[grade]+=subject_dict[s]
#print(flag)
#(6)1教員が1コマあたりに行う授業は1以下
for t in teacher_list:
for d in week:
for p in period:
model += pulp.lpSum(x[d,p,g,c,s] for g in grade_list for c in class_dict[g] for s in subject_list if flag[g,c,t,s]) <=1
#print(model)
#(7)1教員が1日に行う授業数の上下限は、平均値のfloor/ceilとする
#print(t_units)
print(g_units)
for t in teacher_list:
for d in week:
days=len(week)
avg=t_units[t]/days
model += pulp.lpSum(x[d,p,g,c,s] for p in period for g in grade_list for c in class_dict[g] for s in subject_list if flag[g,c,t,s]) <=math.ceil(avg)
model += pulp.lpSum(x[d,p,g,c,s] for p in period for g in grade_list for c in class_dict[g] for s in subject_list if flag[g,c,t,s]) >=math.floor(avg)
#(8)各学年の教員が1コマあたりに行う授業数の上下限は、平均値のfloor/ceilとする
for g in grade_list:
for d in week:
for p in period:
days=len(week)
periods=len(period)
avg=g_units[g]/(days*periods)
model += pulp.lpSum(x[d,p,g,c,s] for c in class_dict[g] for s in subject_list if flag[g,c,t,s]) <=math.ceil(avg)
model += pulp.lpSum(x[d,p,g,c,s] for c in class_dict[g] for s in subject_list if flag[g,c,t,s]) <=math.floor(avg)
model.solve()
print(pulp.LpStatus[model.status])
def export_table(g,c):
timetable_df = pd.DataFrame(index=period,columns=week)
for d in week:
for p in period:
for s in subject_list:
if x[d,p,g,c,s].value() == 1.0:
timetable_df[d][p] = s
print(timetable_df)
export_table(3,1)
export_table(3,2)
export_table(3,3)
export_table(3,4)
export_table(3,5)
export_table(2,1)
export_table(2,2)
export_table(2,3)
export_table(2,4)
export_table(1,1)
export_table(1,2)
export_table(1,3)
export_table(1,4)
model.writeMPS("test.mps")
tmap={}
gmap={}
for t in teacher_list:
for d in week:
for p in period:
for g in grade_list:
for c in class_dict[g]:
for s in subject_list:
if x[d,p,g,c,s].value() == 1.0 and flag[g,c,t,s]:
if t in tmap:
if d not in tmap[t]:
tmap[t][d]=1
else:
tmap[t][d] +=1
else:
tmap[t]={}
tmap[t][d]=1
if g in gmap:
if d not in gmap[g]:
gmap[g][d]={}
gmap[g][d][p]=1
else:
if p not in gmap[g][d]:
gmap[g][d][p]=1
else:
gmap[g][d][p]+=1
else:
gmap[g]={}
gmap[g][d]={}
gmap[g][d][p]=1
print(tmap)
print(gmap)
プロジェクト
プロジェクトは、以下です。
ダウンロード
して、実装の参考にしてください。